El sistema de ficheros. Es la forma en que el sistema operativo organiza los archivos…
Sistema de archivos FAT16 vs FAT32

Os dejo aquí un artículo muy interesante que nos explica claramente el sistema de archivos FAT16 y sus principales diferencias con respecto a FAT32. El artículo original lo encontré en la web
multingles.net/docs/jmt/fat_16_32.htm, aunque desafortunadamente ya no está operativo, «al César lo que es del César».
Y ahora, antes de empezar a hablar de FAT 16 y FAT 32, podíamos hacer un concurso, a ver a quien se le ocurre el mejor sistema de archivos. Tenemos una premisa (ver mis notas anteriores), sabemos que tenemos un «pedazo» del disco para nosotros (partición), en vacío y que somos capaces de recuperar uno a uno, cada sector (512 bytes) de esa partición. Y es todo para nosotros, venga, a quién se le ocurre como almacenar y como recuperar de una manera rápida?
Bueno pasemos de la broma. Empezamos, y sin papel para dibujar, es un poco difícil. A ver como me sale.
MS-DOS, define un concepto nuevo: «cluster», un cluster es una agrupación de sectores (ya veremos cuantos), y es la mínima cantidad de datos que recupera un sistema operativo, y además es una potencia de 2, es decir un cluster pueden ser 1, 2, 4, 8, 16…sectores.
¿Por qué surge el término de cluster?, pues porque como veremos a continuación, es mas complicado manejar «muchos» sectores que «pocos» cluster.
Y otra cosa: hemos dicho que «cluster» es lo mínimo de lo que entiende un sistema operativo. Por tanto nuestros ficheros, independientemente del número de bytes que ocupen, siempre ocuparán un número entero de clúster en el disco. Es decir si nuestro «cluster» es de 32 Kb, y con el Notepad, hemos escrito un documento que sólo tiene la palabra «hola» (4 bytes de longitud), nos da igual. En el disco esto ocupa físicamente («gasta») 32 Kb.
Con lo anterior, empezamos a ver que cuanto más pequeño sea el «cluster», menos espacio perderemos. Es más, lo ideal es que el cluster sea justo lo mínimo que físicamente podemos obtener, es decir un sector (512 bytes).
Si hemos entendido el concepto (y las pegas), del cluster, veamos como podemos hacer nuestro sistema de archivos.
Lo mejor sería tener un índice a los cluster. En un libro, siempre buscamos en un índice la pagina (cluster) que queremos leer, luego ya podemos ir directamente a la pagina. Entonces veamos como se les ocurrió a los padres del MS-DOS, este sistema de índices.
1) Numeramos todos los cluster de nuestra partición. Y se crea una tabla de 2 bytes (16 bits -> FAT 16), al inicio de la partición, con tantos elementos como cluster tengamos en nuestra partición.
2) ¿Y cuántos cluster podemos tener? Un pequeño cálculo. Debido al punto 1), cada elemento de la tabla es de 16 bits. Luego entonces el número máximo que podemos almacenar es 2 elevado a 16, es decir 65536. (menos 1 porque va.mos desde el cero, será 65535). Es decir podemos tener un máximo de 65535 clusters.
3) Ahora dividimos nuestro tamaño de partición por 65535. Pongamos un ejemplo. Supongamos una partición de 827.000.000 bytes. Entonces dividido por 65535 nos da: 12619 bytes. Pero hemos dicho que un cluster eran 1 o 2 o 4 o 8 o 16… sectores. O sea o 512 o 1024 o 2048 o 4096 o 8192 o 16384 ….. Entonces en nuestro caso, debe ser 16384, ya que si fuese más pequeño tendríamos más de los 65535 posibles.
4) Como ya en nuestro disco, hemos prefijado que el cluster es 16384 es decir 16 Kb. Hacemos ahora las operaciones inversas para ver entonces cuántos cluster tenemos: 827.000.000 / 16384 = 50476 cluster.
5) Bien, a continuación, se define un espacio para contener lo que llamamos el directorio raíz del disco. Es un espacio limitado en donde secuencialmente se escribirán los nombres de los archivos (un directorio también es un archivo que contiene los nombres de otros programas…etc.). En este espacio, se escribirá, tanto el nombre como la fecha, los atributos y el «cluster» de comienzo del archivo en el disco.
6) Entonces empecemos. Supongamos un disco vacío. Supongamos que todas las entradas de la FAT (nuestra tabla anterior), se ha rellenado con x’FFFF’ (en hexadecimal, es decir todo a unos binarios. Esto no es verdad, pero para nuestro ejemplo nos vale). Bien entonces nuestro primer archivo contiene un documento, supongamos que de 25.000 caracteres. Y se va a llamar «docu-1.txt».
7) El sistema operativo, primero va al directorio, busca un hueco, en nuestro caso como está vacío lo escribe al principio, escribe la fecha y el tamaño y los atributos del archivo. Y ahora a calcular…
8) ¿Qué ocupa? 25000. ¿Cuánto es el tamaño del cluster? 16384. Bien entonces se necesitan 2 cluster.
9) ¿Cual es el primer cluster libre? Vamos a la tabla de la FAT, y se busca uno que tenga todo a x’FFFF’, esto indica libre. ¿Qué número, posicionalmente, ocupa? Supongamos que el número 300 (ya que los anteriores están marcados como utilizados, porque la propia FAT y el directorio principal ocupan supongamos ese espacio). Bien pues en el directorio ponemos también el numero 300 y en la posición 300 de la FAT ponemos un cero.
10) Como ocupa 2 cluster, busca la siguiente entrada en la FAT, como estaba vacía, encuentra justo el siguiente. El 301. Entonces a la entrada anterior (300) que contiene un cero, le pone 301, y a sí mismo se pone un cero.
11) Ahora se graba el archivo. Los primeros 16384 bytes en el cluster 300 y el resto en el 301.
Y ahora, ¿cómo se recupera el archivo?
Pues fácil. Se va al directorio, y se busca el nombre del archivo. Cuando lo hemos localizado también hemos encontrado el numero mágico 300. Luego ya podemos leer del cluster 300 del disco los primeros 16384 bytes. Ahora, vamos a la FAT a la posición 300 de la tabla. Y allí encontramos un 301, luego vamos al disco y leemos el cluster correspondiente. Luego volvemos a la posición 301 de la FAT y como ya contiene un cero, es que hemos finalizado.
(NOTA para los puristas. Lo del hexadecimal x’FFFF’, y los ceros sabemos que no es verdad. Pero para entenderlo quizá sea el mejor ejemplo)
Bueno pues ya sabemos lo que es FAT16.
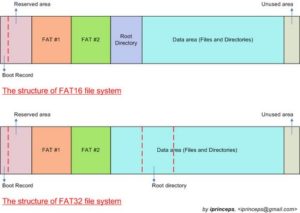
Analicemos ahora sus ventajas y sus inconvenientes:
Ventajas:
1) Mediante una pequeña tablita (máximo de 65535 entradas) y que fácilmente puede residir en memoria ya que serian 65535 * 2 = 128 Kb, tenemos accesibles todos los cluster. Sabemos si están libres u ocupados, etc.
Inconvenientes:
2) Se desperdicia mucho espacio. Ya que por ejemplo en un disco de 2 Gb, el tamaño del cluster es de 32 Kb.
——————————————–
SOLUCION: ¿y que pasa si ahora, aumentamos a 4 bytes (32 bits), el tamaño de cada elemento de la tabla? Bueno entonces podríamos direccionar 2 elevado a 32 clusters, es decir unos 4000 millones de cluster, y por tanto podemos hacer el cluster tan pequeño como queramos. Bien, además por definición, el cluster más pequeño lo hacemos de 4 Kb, ya que es un tamaño bueno, porque también es el tamaño de una página de memoria para el procesador.
Ventajas:
1) Se desperdicia mucho menos espacio. Típicamente yo he medido que en un disco de 2 Gb, obtenemos una mejora del orden del 30% de ahorro.
2) Prácticamente ya no hay un limite para el tamaño de la partición.
Inconvenientes:
2) Típicamente un disco de 2 Gb, tiene ahora 550.000 entradas en la FAT, y además cada una de ellas de 4 bytes, es decir, más de 2 Megas. Para optimizar los accesos deberían estar en memoria física. Luego ya gastamos 2 Mb de memoria física. Y además como esta tabla es grande, se tarda más tiempo en buscar en ella. Típicamente en un pentium 400 se pierde un 7% de velocidad. En procesadores más pequeños esto aumenta drásticamente.
3) Debido al tamaño tan inmenso anterior, cuando todavía está arrancando Windows y está en modo MS-DOS, dicha tabla es intratable en memoria real, y hay que hacer pequeñitos accesos a ella para localizar cualquier archivo o comando. Y pensemos que Windows arranca cientos de ellos antes de poder pasar a modo virtual en 32 bits. Por lo que el arranque de Windows queda muy penalizado.
Y ahora que cada uno juzgue.
¿Queremos velocidad?: FAT 16 y posiblemente varias particiones. Y además penalizado por pérdidas de hasta el 30% en el espacio.
¿Queremos ahorro de espacio?: FAT 32. Ya no hay límites en las particiones. Se penaliza la velocidad y puede que bastante, dependiendo del procesador. Se ahorra espacio.